


































Ogni impresa sta cercando di raccogliere e analizzare i dati di cui dispone per ottenere una migliore comprensione del proprio business oltre che migliorare la cybersecurity. Che si tratti di file di log, metriche di sensori o altri dati non strutturati, la maggior parte delle imprese gestisce e rende disponibili i dati all’interno di un data lake, sfruttando poi varie applicazioni come strumenti ETL, motori di ricerca e database per l’analisi. Si tratta di un’architettura che aveva decisamente senso quando era presente un flusso coerente e prevedibile di dati da elaborare. In realtà, la maggior parte delle aziende sta cercando di raccogliere flussi di dati tanto voluminosi quanto imprevedibili che spesso portano i requisiti di elaborazione a cambiare e a diventare rapidamente piuttosto complessi. La capacità di gestire e setacciare petabyte di dati può mettere a dura prova qualsiasi forma di analisi, fino a impedire la capacità di ottenere informazioni tempestivamente.
Di quali dati hanno bisogno le aziende?
I clienti, dai responsabili aziendali ai singoli sviluppatori, ci raccontano che la loro più grande sfida è trovare le informazioni giuste al momento giusto, proprio come cercare un ago in un pagliaio. Il business è così impreparato di fronte all’eccesso di dati che perdersi un evento o un’informazione importante è diventata la norma. La capacità di avere i dati giusti può determinare il successo o il fallimento di un’impresa. Affrontare questa sfida in modo corretto può significare prendere decisioni di acquisto al miglior prezzo, migliorare i processi aziendali per risparmiare milioni di costi operativi, o aiutare il team di sicurezza IT a migliorare la cybersecurity attraverso il rilevamento veloce delle minacce informatiche, riducendo al minimo il rischio di esporre dati riservati.
Cosa dovrebbero considerare i responsabili IT quando pianificano le loro esigenze in termini di dati? L’azienda dovrebbe mantenersi fedele alla vecchia metodologia del data lake? O ripensare radicalmente il problema dei dati, andando a raccogliere solo quelli che contano?
Una data strategy che cambia: il caso di una grande azienda del settore oil and gas
Un’organizzazione globale nel mercato oil and gas raccoglie, trasforma e invia al proprio SIEM ogni giorno centinaia di terabyte di dati di log provenienti da desktop, server e applicazioni. Man mano che l’azienda si evolve in una strategia ibrida e multi-cloud, si ha bisogno di iniziare a raccogliere applicazioni, server e log di rete dal cloud. Di fronte a una data strategy che iniziava a cambiare e con l’obiettivo di migliorare la cybersecurity il team di sicurezza informatica si è imbattuto nei seguenti problemi:
- Enormi volumi dati da analizzare in continua crescita, con grande difficoltà nella interpretazione degli stessi.
- Impossibilità nell’effettuare analisi ad hoc una volta che i dati sono nel SIEM. Inoltre, risulta essere troppo costoso lo spostamento successivo dei dati in un’altra applicazione per analisi specifiche.
- Le licenze delle applicazioni di Cybersecurity e i costi dell’infrastruttura aumentano più velocemente della capacità di rilevare efficacemente gli eventi informatici.
Perché non avviare l’elaborazione dei dati sull’edge?
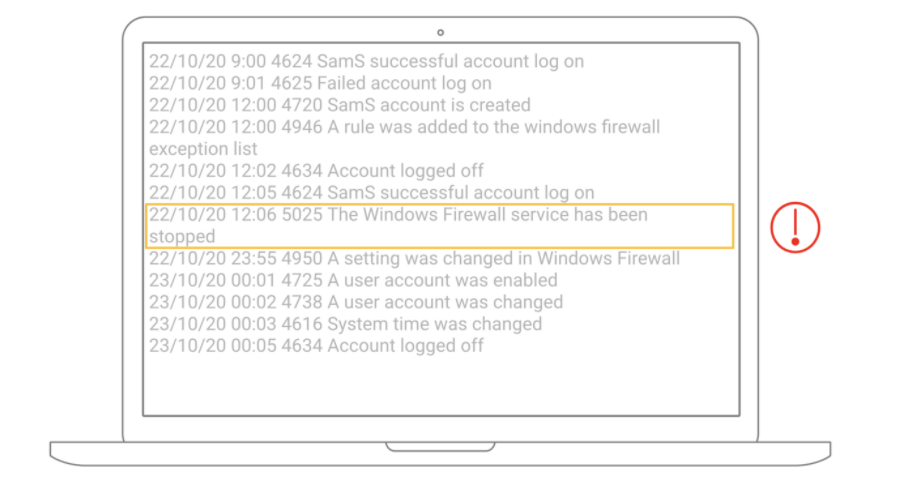
Ogni dispositivo può registrare le attività dell’utente, che si tratti di accedere ai dispositivi o di cambiare la password. La maggior parte di questi eventi sono attività comuni, ma il team di cybersecurity si preoccupa solo degli eventi insoliti che contano (come evidenziato nell’immagine). Piuttosto che raccogliere ogni singolo evento e analizzarlo in seguito, ha molto più senso identificare i dati importanti nel momento stesso in cui vengono raccolti. Quale soluzione può aiutare a raccogliere solo gli eventi?
Trasformiamo il primo miglio della pipeline di dati
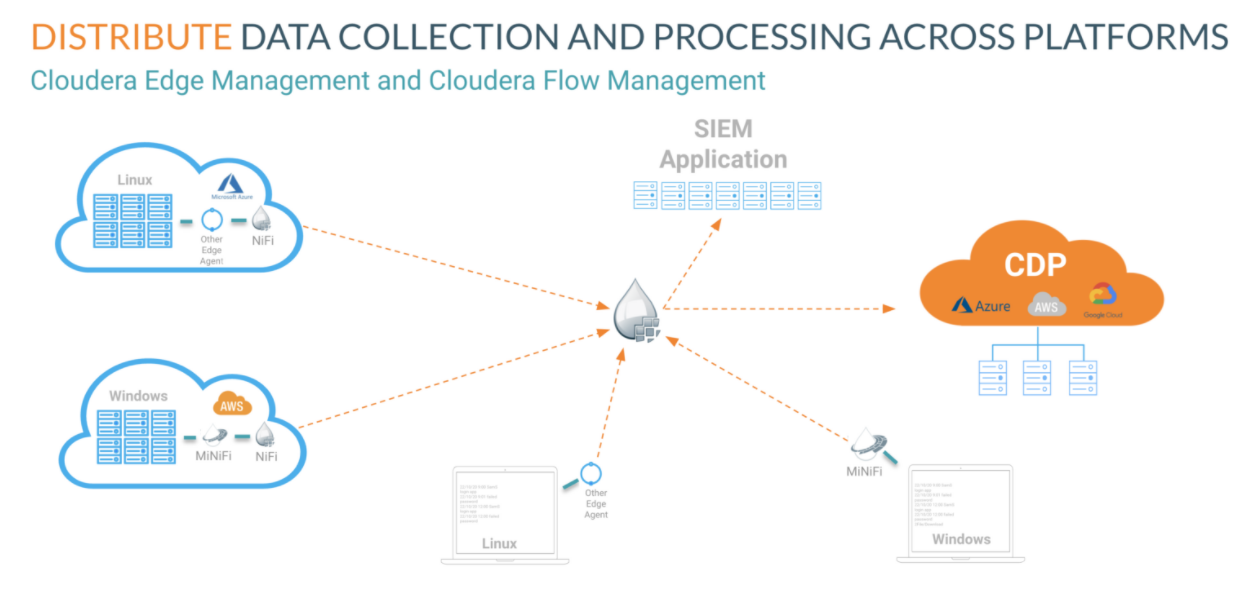
Cloudera Edge Management, che include un leggero agente edge, alimentato da Apache MiNiFi, è stato distribuito su ogni desktop, server, rete e applicazione dagli elementi collocati on-premises fino al cloud pubblico per raccogliere i dati di log. Invia i dati a Cloudera Flow Management, alimentato da Apache NiFi, per analizzare, trasformare e distribuire i dati ad alta priorità importanti per il SIEM e fornisce i dati rimanenti al cloud pubblico per eventuali ulteriori analisi. La capacità di gestire il flusso e la trasformazione dei dati durante il primo miglio della pipeline e di controllare la distribuzione dei dati può accelerare le prestazioni di tutte le applicazioni analitiche e migliorare la cybersecurity aziendale.
Qual è l’impatto sul business?
L’azienda si rende conto che rivedere in questo modo il primo miglio della pipeline di dati può accelerare i processi di analisi esistenti, e sta diventando il nuovo approccio per modernizzare tutte le loro analisi. In questo scenario, Cloudera Edge e Flow Management sono stati implementati per analizzare e trasformare i dati di log XML in JSON e distribuire i risultati al SIEM. Controllando l’elaborazione dei flussi di dati, si potrà migliorare la cybersecurity in quanto, il team di sicurezza informatica può effettuare le ricerche di Splunk con velocità del 55% superiore e ottenere una visione rapida delle potenziali frodi.

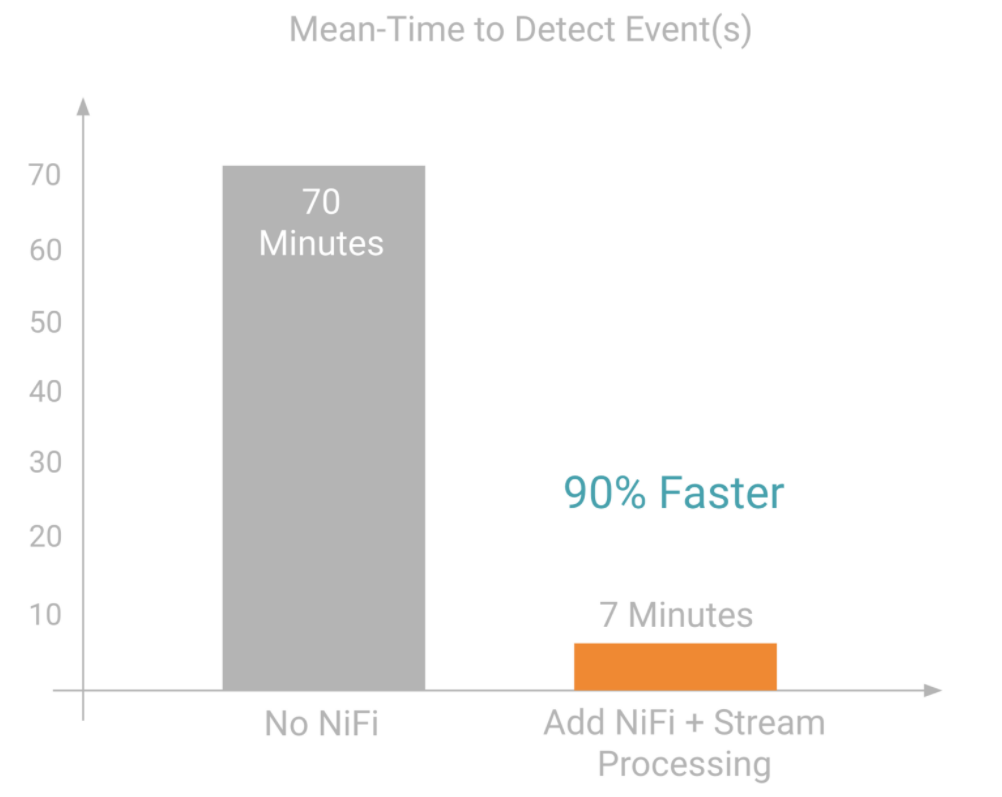
Ecco un altro esempio: il sistema di scoring impiega 70 minuti per identificare l’accesso di un cybercriminale al sistema informatico e rilevarne l’intrusione. Aggiungendo Cloudera Flow Management con un motore di elaborazione dei flussi, il “tempo medio per rilevare gli eventi” si è ridotto a 7 minuti, con un miglioramento del 90%.
Rendendo più moderno il flusso di dati, l’azienda ha ottenuto una migliore comprensione del business.Hanno anche ridotto i terabyte di dati inseriti, andando ad abbattere significativamente (del 30%) i costi dell’infrastruttura e delle licenze.
Modernizzando il flusso di dati sarà possibile ottenere più rapidamente una vista d’insieme, migliorando il tempo per prendere decisioni ad-hoc, riducendo il rischio e promuovendo l’innovazione in tutta la tua di business.
di Fabio Pascali, Regional Director, Cloudera




















