

")































Gli assistenti di programmazione basati su AI, noti anche come copilot, stanno trasformando il modo in cui si sviluppano i software, offrendo suggerimenti, spiegazioni e correzioni di codice sia a sviluppatori esperti che a principianti. Per gli sviluppatori esperti, questi tool riducono il lavoro ripetitivo, velocizzano l’esplorazione di nuove idee e permettono di concentrarsi su task di codifica complessi. Per studenti e appassionati di AI, rappresentano un supporto che accelera l’apprendimento, illustrando diversi approcci di implementazione e spiegando in modo chiaro il funzionamento del codice.
Gli assistenti di programmazione possono funzionare sia in cloud sia in locale. Quelli cloud sono accessibili ovunque ma richiedono abbonamenti e possono avere limitazioni. Gli assistenti locali evitano queste restrizioni, ma necessitano di hardware potenti per funzionare al meglio.
Le GPU NVIDIA GeForce RTX forniscono l’accelerazione hardware necessaria per eseguire efficacemente gli assistenti locali.
Coding incontra l’AI generativa
Nello sviluppo software tradizionale, molte attività ripetitive come consultare documentazione, cercare esempi, scrivere codice boilerplate, mantenere la sintassi corretta, individuare bug e documentare le funzioni possono sottrarre tempo prezioso alla progettazione e alla risoluzione dei problemi. Gli assistenti di codifica semplificano queste fasi, liberando gli sviluppatori per concentrarsi su ciò che conta davvero.
Molti assistenti AI si integrano direttamente nei flussi di lavoro esistenti, con supporto all’interno dei principali IDE come Microsoft Visual Studio Code o JetBrains PyCharm.
Gli assistenti di codifica possono operare in cloud o in locale.
Gli assistenti basati su cloud richiedono l’invio del codice sorgente a server esterni per l’elaborazione e la restituzione delle risposte. Questo approccio può risultare più lento e soggetto a limiti di utilizzo. Inoltre, molti sviluppatori preferiscono mantenere il proprio codice in locale, soprattutto quando lavorano su progetti sensibili o proprietari. Gli assistenti cloud richiedono spesso abbonamenti a pagamento per accedere a tutte le funzionalità, creando barriere per studenti, hobbisti o team con budget limitati. Gli assistenti locali eliminano questi problemi, mantenendo il codice sul dispositivo e garantendo maggiore privacy e controllo. Tuttavia, per funzionare in modo efficiente, richiedono hardware performanti.
Gli assistenti di codifica funzionano in un ambiente locale, consentendo un accesso gratuito con:
Gli assistenti di codifica in esecuzione locale su NVIDIA RTX offrono numerosi vantaggi.
Inizia con gli assistenti di codifica locali
I tool che semplificano l’esecuzione degli assistenti di codifica in locale includono:
- dev — Un’estensione open source per l’IDE VS Code che si connette a modelli linguistici di grandi dimensioni (LLM) locali tramite Ollama, LM Studio o endpoint personalizzati. Questo tool offre chat nell’editor, completamento automatico e supporto per il debug con configurazione minima. Inizia con Continue.dev utilizzando il backend Ollama per l’accelerazione RTX locale.
- Tabby — Un assistente di codifica sicuro e trasparente, compatibile con molti IDE e in grado di eseguire l’AI su GPU NVIDIA RTX. Questo strumento offre il completamento del codice, la risposta alle domande, la chat in linea e altro ancora. Inizia con Tabby su PC NVIDIA RTX AI.
- OpenInterpreter — Interfaccia sperimentale ma in rapida evoluzione che combina LLM con accesso alla riga di comando, modifica dei file ed esecuzione di attività agentiche. Ideale per l’automazione e le attività di tipo devops per gli sviluppatori. Inizia a utilizzare OpenInterpreter su PC NVIDIA RTX AI.
- LM Studio — Runner con interfaccia grafica per LLM locali che offre chat, gestione delle finestre contestuali e prompt di sistema. Ottimale per testare i modelli di codifica in modo interattivo prima della distribuzione IDE. Inizia a utilizzare LM Studio su PC NVIDIA RTX AI.
- Ollama — Un motore di inferenza di modelli AI locale che consente un’inferenza veloce e privata di modelli come Code Llama, StarCoder2 e DeepSeek. Si integra perfettamente con strumenti come Continue.dev.
Questi tool supportano modelli forniti tramite framework come Ollama o llama.cpp e molti sono ora ottimizzati per GeForce RTX e GPU NVIDIA RTX PRO.
Come l’AI su NVIDIA RTX accelera il tuo apprendimento
Eseguito su un PC con tecnologia NVIDIA GeForce RTX, Continue.dev abbinato al Gemma 12B Code LLM aiuta a spiegare codice esistente, esplorare algoritmi di ricerca e risolvere problemi, il tutto direttamente sul dispositivo. Come un assistente didattico virtuale, fornisce spiegazioni in linguaggio semplice, commenti contestualizzati, suggerimenti in linea e indicazioni per migliorare il codice in base al progetto su cui stai lavorando.
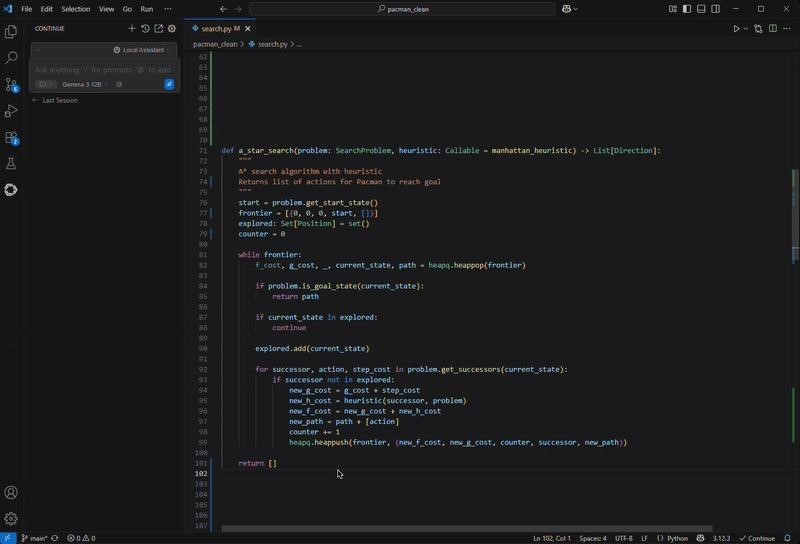
Questo flusso di lavoro dimostra i vantaggi dell’accelerazione locale: l’assistente è sempre disponibile, risponde in tempo reale e offre supporto personalizzato, mantenendo il codice privato sul dispositivo e trasformando l’apprendimento in un’esperienza immersiva.
Questo livello di reattività è possibile grazie all’accelerazione GPU. Modelli come Gemma 12B richiedono potenza di calcolo significativa, soprattutto con prompt lunghi o su progetti con più file. Eseguirli localmente senza GPU può rallentare anche le operazioni più semplici. Con le GPU NVIDIA RTX, i Tensor Core accelerano l’inferenza direttamente sul dispositivo, mantenendo l’assistente veloce e reattivo, perfetto per un flusso di sviluppo attivo.
Che si tratti di lavori accademici, bootcamp di programmazione o progetti personali, i PC RTX AI consentono agli sviluppatori di creare, imparare e iterare più velocemente con strumenti basati su IA.
Per chi inizia ora, in particolare studenti che stanno sviluppando competenze o sperimentando l’AI generativa, i laptop NVIDIA GeForce RTX serie 50 offrono tecnologie IA dedicate per accelerare le migliori app per apprendimento, creazione e gaming su un unico dispositivo.
E per incoraggiare sviluppatori e appassionati di AI a sperimentare l’AI locale e potenziare i propri PC RTX, NVIDIA ospita il Plug and Play: Project G–Assist Plug–In Hackathon, che si terrà virtualmente fino a mercoledì 16 luglio. I partecipanti potranno creare plug-in personalizzati per Project G–Assist, l’assistente AI sperimentale progettato per rispondere al linguaggio naturale e integrarsi con strumenti creativi e di sviluppo. È un’opportunità per vincere premi e mostrare le potenzialità dei PC RTX AI.
Unisciti al server Discord di NVIDIA per connetterti con sviluppatori e appassionati di IA e scoprire insieme le potenzialità dell’IA su RTX.






 2024/1689: la nuova disciplina Europea sull’intelligenza artificiale.")














