


































Fino a non molto tempo fa, i database erano considerati sostanzialmente dei monoliti, mai destinati a essere suddivisi in microservizi e containerizzati. In poco tempo sono cambiate molte cose e, sebbene la containerizzazione di un database possa non essere così semplice come quella di un’applicazione, i vantaggi superano di gran lunga i problemi. I database su container offrono l’agilità, la portabilità e la scalabilità di cui le organizzazioni hanno bisogno e, per questo motivo, sempre più aziende si stanno muovendo per sfruttare questi vantaggi.
Un recente studio sponsorizzato da Red Hat e condotto da Gartner Peer Insights ha coinvolto 200 leader tecnologici di tutto il mondo per comprendere come le organizzazioni stanno adottando i database su container e Kubernetes, quali tecnologie stanno prendendo in considerazione per distribuire questi carichi di lavoro e altro ancora. Il report completo è
Cresce l’adozione – e aumentano i differenti casi d’uso
La stragrande maggioranza degli intervistati è sulla buona strada per operare i propri database su container, con il 69% che dichiara di trovarsi in una fase intermedia o avanzata dell’adozione. Di questo 69%, il 4% ritiene di essere molto avanti nel processo e il 65% di trovarsi a metà strada, avendo iniziato l’adozione, ma non li sta ancora utilizzando in modo completo.
Inoltre, dato il numero di strumenti ora disponibili a supporto dell’adozione, questi numeri sono probabilmente destinati a crescere. Operatori Kubernetes e grafici Helm aiutano ad automatizzare le operazioni iniziali, quali l’installazione, la configurazione, gli aggiornamenti e gli upgrade, oltre a contribuire alla gestione del ciclo di vita delle applicazioni, semplificando notevolmente l’adozione e la manutenzione continua per le organizzazioni.
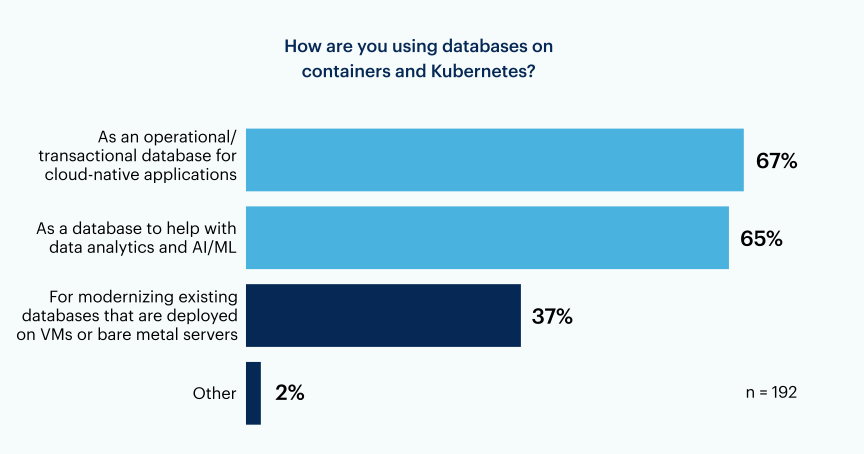
I motivi dell’adozione sono vari, con i casi d’uso operativi o transazionali al primo posto, come riportato da due terzi (67%) degli intervistati. Quasi alla pari con i casi d’uso operativi, il 65% degli intervistati utilizza i database su container e Kubernetes per contribuire all’analisi dei dati e all’AI/ML. Un numero significativo di intervistati (37%) sta utilizzando i container per modernizzare i propri database tradizionali, distribuiti su macchine virtuali o server bare metal.
Diverse metodologie di implementazione
La ricerca di Red Hat non si è soffermata solamente sulle tecnologie dei database utilizzate dalle aziende intervistate, ma ha anche analizzato le metodologie selezionate per la loro implementazioni. È emerso come il 61% degli intervistati abbia adottato una modalità DBaaS – Database as a Service – fornita da cloud provider come AWS, Azure e Google Cloud. Il 52%, invece, si è orientato verso database cloud-native, quali ad esempio Crunchy Data, CouchBase e MongoDB.
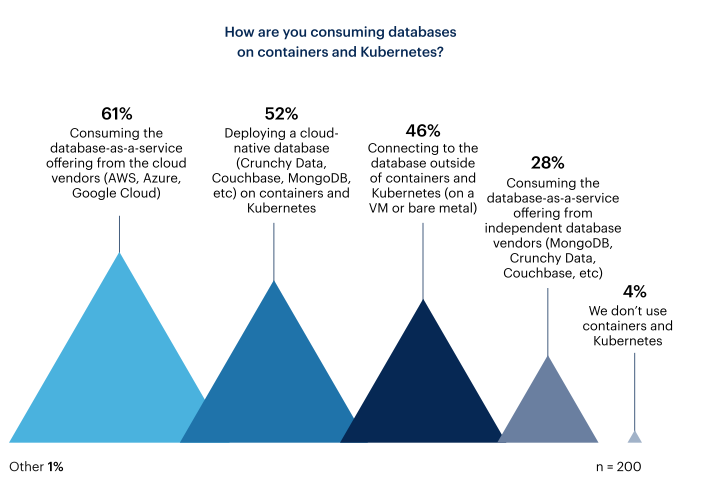
Alla domanda su come la loro organizzazione intende consumare i database tra due anni, i risultati sono stati simili, ma mostrano un aumento sia degli intervistati che prevedono di implementare un database cloud-nativo sia di quelli che prevedono di consumare un’offerta DBaaS di fornitori di database indipendenti. Gli intervistati che prevedono di connettersi ai database al di fuori di container e Kubernetes sono in calo, il che suggerisce che un numero maggiore di organizzazioni desidera adottare i database su container e Kubernetes.
I database sono ovunque – anche sull’edge
L’edge computing ha aperto alle organizzazioni nuove opportunità di offrire nuovi insight ed esperienze. Poiché le decisioni importanti relative ai dati avvengono ai margini della rete, le organizzazioni stanno riconsiderando dove archiviare i dati, alla luce delle considerazioni sulla privacy, sulla sicurezza e sulla conformità.
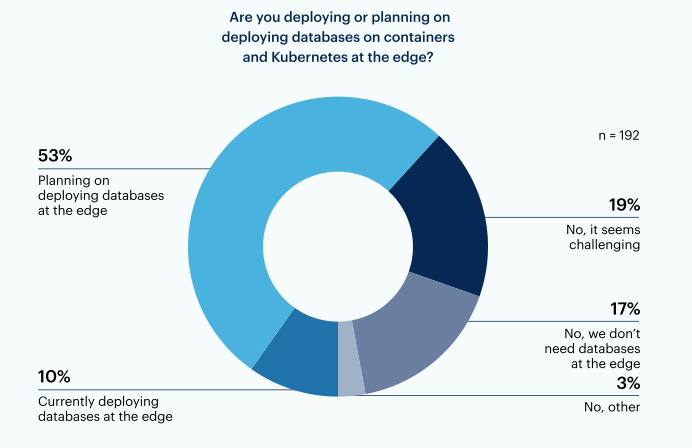
La maggioranza degli intervistati (63%) sta attualmente implementando o pianificando l’implementazione di database su container e Kubernetes nell’edge.
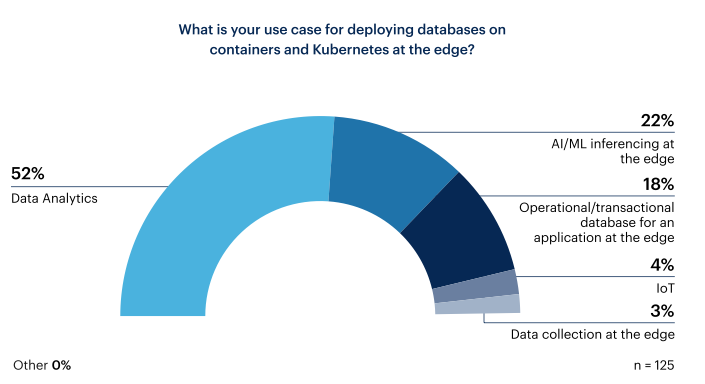
Tra coloro che prevedono di implementare i database su container e Kubernetes nell’edge, quasi tre quarti (74%) prevedono di utilizzarli per l’analisi dei dati o per l’inferenza AI/ML nell’edge. Al contrario, solo il 18% ha dichiarato di aver bisogno di un database operativo/transazionale per un’applicazione edge.
La necessità di soluzioni ibride
Database e data analytics sono parte integrante delle applicazioni cloud-native e accelerano ingestione, archiviazione, elaborazione e analisi dei dati. I database containerizzati sono diventati un’utilità on-demand che è parte integrante dell’applicazione stessa.
Gli utenti Kubernetes spesso utilizzano più metodi differenti per integrare i servizi di dati nei loro cluster, con una combinazione di database nel cloud, database distribuiti direttamente attraverso Kubernetes e anche connessione a macchine virtuali che eseguono servizi di dati al di fuori del cluster. Una piattaforma che permetta tutte e tre le cose, come Red Hat OpenShift, è fondamentale per l’agilità degli sviluppatori.
























